JavaScriptでasync/awaitの備忘録
JavaScriptの復習
JavaScriptはシングルスレッドで動いています。 つまり、call stack(コードを読み込み、実行するもの)が一つしかないので、処理を一つずつ実行していくようになっています。
非同期処理の必要性
順番に処理が実行されていく中で、仮に時間のかかる処理が一つ間にあった場合、Javascriptがその処理をしている間に他のものは実行されません。
そこで重たい処理をJavascript以外に任せられたらJavaScriptは処理をすすめることができますよね?
それを可能にしたのが非同期処理ということです。
非同期処理の例
非同期処理が行えるオブジェクトとしてPromise developer.mozilla.org
があります。async/awaitを理解するためにはPromiseを理解しないといけないです。Promiseが返ってくるfetch()を使った例を紹介します。 fetch()はHTTPリクエストの発行とレスポンスを取得する関数です。
JSONPlaceholder - Fake online REST API for testing and prototyping
というサイトを使ってAPIを叩いて見ます。ブラウザの検証を開き、consoleで試しにfetch()を実行してみます。
fetch('https://jsonplaceholder.typicode.com/todos/1')
するとPromiseが帰ってきているのがわかります。
続いて、
fetch('https://jsonplaceholder.typicode.com/todos/1')
.then(response => response.json())
.then(json => console.log(json))
を実行してみると、JSONのデータが帰って来ていることが確認できます。
これがPromiseを使った書き方です
async/awaitについて
async functionは呼び出されるとPromiseを返します。 awaitはPromiseの結果が帰って来るまで待機しておく演算子のことです。 awaitはasync function内でないと利用できないです。
async/awaitの例
先程の例をasync/awaitを使って同様の処理を書いてみると
const fetchTodos = async function(){ const response = await fetch('https://jsonplaceholder.typicode.com/todos/1') const data = await response.json() console.log(data) } fetchTodos()
先程と同様の結果が帰ってきます。
このようにPromiseで連結された処理を多用するよりもasync/awaitを使って読みやすく書くことができます。
そんな変わらないじゃん。むしろ、Promiseほうがわかりやすいと思った方もいるかもしれません。
もう少し複雑な例を使って見ましょう。
Promise chainの場合
const routes = [ 'todos', 'posts', 'users' ] const baseUrl = 'https://jsonplaceholder.typicode.com/' Promise.all(routes.map(route => fetch(baseUrl+route + '/1').then(res => res.json()) )).then(array => { console.log('todos', array[0]) console.log('posts', array[1]) console.log('users', array[2]) }).catch("Error")
async / awaitを使った場合
const fetchData = async function(){ try { const [todos, posts, users] = await Promise.all(routes.map(route => fetch(baseUrl+route + '/1').then(res => res.json()) )) console.log('todos', todos) console.log('posts', posts) console.log('users', users) } catch(e) { console.log('Error, ', e) } }
JSの復習として、非同期処理の説明やasync/awaitの書き方について紹介しました。
どこか間違った部分があれば、教えていただければ幸いです。
yahoo web APIのルビ振り使ってみた
こんにちは、がじゅまるです
今日はyahoo web APIのルビ振りを使ってみたいと思います
漢字かな交じり文に、ひらがなとローマ字のふりがな(ルビ)が返ってくるAPIです。
このAPIを使ってPythonで簡単なスクリプトを書いていきます。
Yahooのディベロッパーでアプリケーションを登録
Yahoo!JAPANのアプリケーションを登録します。登録にはYahooのIDが必要です。
アプリケーション登録画面ではWeb APIを利用する場所としてサーバーサイドとクライアントサイドが選べます。
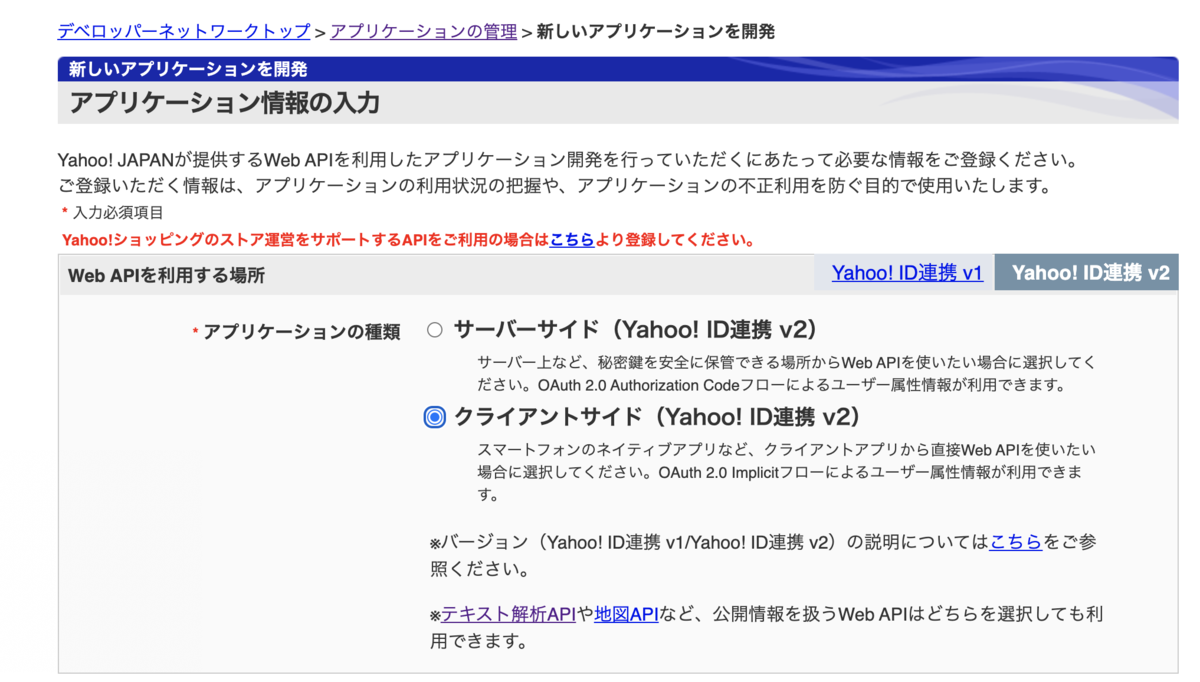 今回使うルビ振りはどちらでも使えるのでクライアントサイドを選びます。
今回使うルビ振りはどちらでも使えるのでクライアントサイドを選びます。
アプリケーションの基本情報 などを入力していくと登録できます。今回は簡単なスクリプトを書くだけなので、特に基本情報の登録はデフォルトのままで大丈夫です
登録すると、アプリケーションの情報が見れるようになります。
そこにClient IDがあるのでそのIDを使ってスクリプトを書いていきます。
Pythonスクリプト実装
ルビ振りではふりがなを付ける対象のテキスト(sentence)と学年(grade)、 yahooのアプリケーション登録したClient ID(appid)がリクエストパラメータとしてあります。
gradeは小学校何年生までの漢字にルビをつけるかといったものとなっています。
def build_yahoo_furigana_data(sentence: str, grade: int = 1) -> Dict[str, str]: validate_grade(grade) # 対応しているgradeかどうかをチェック return { "appid": YAHOO_APP_ID, #ClientIDをここに "grade": grade, "sentence": sentence }
yahoo furigana serviceにPOSTする際の形式に合わせた関数。
それを使ってpythonのrequestsとxmltodictを使っていきます。 APIの返り値がxmlになっているのでそれをdictに変換するパッケージとしてxmltodictを使います。
https://developer.yahoo.co.jp/webapi/jlp/furigana/v1/furigana.html
def make_furigana(sentence: str, grade: int) -> str: target_url = "https://jlp.yahooapis.jp/FuriganaService/V1/furigana" data = build_yahoo_furigana_data(sentence, grade) response = requests.post(target_url, data=data) parsed_xml = xmltodict.parse(response.text) words = list(parsed_xml['ResultSet']['Result']['WordList'].values())[0] output_sentence = [] for word in words: if word.get("Furigana", ""): output_sentence.append(word["Furigana"]) else: output_sentence.append(word["Surface"]) return "".join(output_sentence)
やっていることとしてはAPIのresponseに対してdictに変換します。
そこから必要なWordListの値をlistにして、ふりがなのwordをoutputに連結させていきます。
そのoutputのlistを文字列として連結させることで、ふりがなを振った文字列が完成します。
def main(args): # sentence = "今日は猛暑日だ" sentence = args.sentence grade = args.grade output = make_furigana(sentence, grade) print(f"input: {sentence}") print(f"output: {output}") if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--sentence', '-s', required=True) parser.add_argument('--grade', '-g', type=int, default=1) args = parser.parse_args() main(args)
後は、argparseを使って引数を渡せるようにすれば、完成です。 適当にnewsから取ってきた一文をふりがなに変換させてみます
結果
$ python furigana_service/furigana.py -s 米大統領選で当選を確実にした民主党のジョー・バイデン前副大統領 input: 米大統領選で当選を確実にした民主党のジョー・バイデン前副大統領 output: べいだいとうりょうせんでとうせんをかくじつにしたみんしゅとうのジョー・バイデンぜんふくだいとうりょう
Pythonで開発する際のおすすめ環境セットアップ
こんにちは、がじゅまるです!
都内のIT企業でエンジニアとして働いています。
Python歴は2年くらいな「がじゅまる」が
Pythonでの開発をする際のおすすめの開発環境を紹介します。
Pythonの環境は人によって好みが大きく分かれると思いますがあくまで一例として見ていただければと思います。
TL;DR
結論から言いますとvenv + poetryを使い、IDEはPyCharmを使います。
venvについて
venvとはPython公式が提供する仮想環境マネージャーです。
利点としてはPythonインタプリタとパッケージの組み合わせを好きなだけ作り、レポジトリごとに分離することができる点です。
毎回activateする手間はありますが、aliasを作っておけばさほど手間ではありません。 また、後ほど説明するPyCharmでは、そのプロジェクトを開けば、PyCharmのterminalでは自動でvenvをactivateしてくれます。
$ cd (開発するレポジトリ) $ python3 -m venv .venv $ source ./.venv/bin/activate
python3の -m venv {任意の名前} なので自分の使いたいようにセットできます。 レポジトリごとにその名前にするのはactivateする際に面倒なので統一してaliasを作っておくことをおすすめします。
poetryの紹介
poetryはpyproject.tomlベースでプロジェクト管理をしてくれるツールです python-poetry.org
pyproject.tomlがあることでsetup.pyを書かなくてもよくなります。
ツールごとに名前空間 tool.${toolname} を作って独自設定を記述することが出来きます。
パッケージ依存関係をよしなにやってくれます。よしなにやってくれる代わりにインストールに時間がかかります。
CIとかでpackageインストールする場合はpoetryのpyproject.tomlからrequirement.txtを吐き出してくれるコマンドがあるので それを使ってpip installすると高速化できます。
(poetryからvenvと同じ様なことはできるのですが、設定によってはバグったりするのでvenvを紹介してます)
PyCharmの紹介
今までsublime text, atom, vscode, vimなどのエディタを使ってきましたが、 PyCharm最強だなという結論に至りました。
PyCharm www.jetbrains.com
何を隠そうPyCharmを使い始めてから、Python開発がより楽しくなりました!
PyCharmのどこがいいの?
強力なlint checkと補完機能
Pythonは動的型付き言語ですが、type-hintingを使えば、静的型付き言語のような強力な補完機能がかなり役立ちます。
type hintingを使えば、importしたpackageに生えているclassやmethodが補完候補としてみれます。
さらには、methodの引数まで表示してくれるので、どんな引数があったかを忘れても調べる必要がありません。
定義元へのjumpが優秀
vscodeとかでもメソッドの定義元へのジャンプの機能はありますが、それよりも優秀です。
packageの中まで飛んでくれるので、補完で良さそうなメソッドを見つけて楽に挙動を確認できたりします。
便利なTODO一覧機能
ソースに書いたTODOコメントの一覧化できる機能です。地味に便利です。TODOの他にもFIXMEも拾ってくれます。

他には、githubのconflict解消がわかりやすくできたり、リファクタリング機能も優秀だったり、 他にもまだまだ便利な機能やPluginがたくさんあるので調べてみてください。
まだ使ったことないって方は騙されたと思って一度使って見てください!
まとめ
venv + poetry + PyCharmで楽しくPython開発しましょう!